
 Science is like a ratchet. Each discovery builds upon previous work, and ideas that withstand scrutiny become stepping stones to future progress. Competition can be fierce, but good scientists credit their predecessors and accept critique with grace in a perennial collaboration toward greater knowledge. That’s the beauty of science.
Science is like a ratchet. Each discovery builds upon previous work, and ideas that withstand scrutiny become stepping stones to future progress. Competition can be fierce, but good scientists credit their predecessors and accept critique with grace in a perennial collaboration toward greater knowledge. That’s the beauty of science.
The ratchet is evident in the evolution of relationship prediction tools for genealogy. The DNA testing companies all suggest ranges of relationship for our DNA matches, like “2nd–3rd cousin,” but independent genealogists have been instrumental in pushing the field forward.
The bedrock of relationship prediction is the Shared cM Project by Blaine Bettinger, which has amassed data for more than 60,000 known relationships since 2015. Although not a predictive tool itself, its statistical approach to DNA matches inspired the first use of probabilities to evaluate them. (See below for a more detailed timeline.)
We now have several tools that assign relationship probabilities to autosomal DNA matches, including the recently announced cM Explainer from MyHeritage. But which tool is best? What does “best” even mean in this context?
No tool will predict the correct relationship 100% of the time; DNA inheritance is too random for that. And no prediction can be accepted without further investigation. Even for a “parent–child” match, we must consider which person is older and whether an identical twin exists.
A tool should make our work easier. It should point us in the right direction without misleading us or giving false confidence. An incorrect prediction, or an overly confident one, can send us down a rabbit holes and waste our time.
I suggest the following criteria for which relationship predictor is “best:”
- It predicts the correct relationship as the top-ranked option more frequently than others, across the spectrum of shared DNA amounts.
- It predicts the correct relationship with more confidence. A tool that correctly predicts a 2nd cousin at 68% probability is better than one that gives the same match a 47% chance of being a 2C.
- When it’s wrong, the true relationship is still ranked within the top three possibilities.
- When it’s wrong, the true relationship has a similar probability to the top-ranked one. A wrong prediction that scores only 1% less than the incorrect one is better than a wrong prediction that scores 30% less.
You can help!
Blaine Bettinger and I are collaborating on a study to compare three different relationship prediction tools: the original Shared cM Tool at DNA Painter, the Shared cM Tool with updated probabilities, and the cM Explainer at MyHeritage. For matches in the AncestryDNA database, you can also evaluate their built-in probabilities. (A fourth tool was originally included in this study but was removed after strong objections by its developer.)
We are soliciting volunteers in two ways. If you prefer to work with your own DNA kits, you can fill out this online survey. Each pass through the survey will prompt you to evaluate the same match in different tools. To get started, you’ll want to have handy: the known relationship, the amount of shared DNA in centimorgans, the number of segments, and (if possible) the age of the DNA match. You can submit as many matches as you like by going through the survey multiple times.
Alternately, you can help by using data from the Shared cM Project. Blaine has collected shared DNA amount and number of segments for about 40,000 pairs of known relatives. This means we can quickly and efficiently process large amounts of data. The one parameter missing is age (used by the MyHeritage tool), which is why we’re giving volunteers a choice of how to contribute. To help this way, see the dedicated post in the Genetic Genealogy Tips & Techniques group on Facebook.
Timeline of Relationship Prediction Tools
The list below is by no means comprehensive. Instead, it’s meant to acknowledge the key advances in the field and introduce the main options for relationship prediction in the survey described above.
 2015–Blaine Bettinger launched the crowdsourced Shared cM Project. Today, it has amassed more than 60,000 data points that provide averages, ranges, and histograms for shared DNA between known relatives. The project was foundational for interpreting DNA matches. All data comes from volunteers, but the sheer size of the dataset should, in theory, outweigh occasional errors.
2015–Blaine Bettinger launched the crowdsourced Shared cM Project. Today, it has amassed more than 60,000 data points that provide averages, ranges, and histograms for shared DNA between known relatives. The project was foundational for interpreting DNA matches. All data comes from volunteers, but the sheer size of the dataset should, in theory, outweigh occasional errors.
 2016–Christa Stalcup and The DNA Detectives group produced “The Green Chart,” compiling similar information to the Shared cM Project but from relationships that were vetted by experienced genealogists. This more-careful approach necessarily yields less data. (This is a perennial trade-off in science.)
2016–Christa Stalcup and The DNA Detectives group produced “The Green Chart,” compiling similar information to the Shared cM Project but from relationships that were vetted by experienced genealogists. This more-careful approach necessarily yields less data. (This is a perennial trade-off in science.)
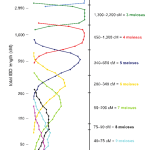 2016–AncestryDNA published a Matching White Paper with a key graph (Figure 5.2) that allowed us to take a more statistical approach to relationship prediction. Instead of simply showing which relationship groups shared the same amounts of DNA, it indicated which were more likely for any given centimorgan amount.
2016–AncestryDNA published a Matching White Paper with a key graph (Figure 5.2) that allowed us to take a more statistical approach to relationship prediction. Instead of simply showing which relationship groups shared the same amounts of DNA, it indicated which were more likely for any given centimorgan amount.
 2017–Jonny Perl integrated two datasets–the Shared cM Project and Ancestry’s Figure 5.2–to create the Shared cM Tool. This was the first interactive tool to provide statistical probabilities for relationships and has become the gold standard for DNA-based prediction, both for its ease of use and its accuracy.
2017–Jonny Perl integrated two datasets–the Shared cM Project and Ancestry’s Figure 5.2–to create the Shared cM Tool. This was the first interactive tool to provide statistical probabilities for relationships and has become the gold standard for DNA-based prediction, both for its ease of use and its accuracy.
 2017–Professor Andrew Millard performed computer simulations to show that the number of segments can sometimes help distinguish among close relationships that have the same expected total of shared DNA. This concept built on an earlier scientific publication by 23andMe scientists in 2012.
2017–Professor Andrew Millard performed computer simulations to show that the number of segments can sometimes help distinguish among close relationships that have the same expected total of shared DNA. This concept built on an earlier scientific publication by 23andMe scientists in 2012.
![]() 2019–AncestryDNA began reporting relationship probabilities in their DNA match lists. These probabilities are occasionally been updated. To date, they have not produced a white paper explaining their methods.
2019–AncestryDNA began reporting relationship probabilities in their DNA match lists. These probabilities are occasionally been updated. To date, they have not produced a white paper explaining their methods.
 2023–Brit Nicholson introduced the interactive SegcM, a tool that predicts relationships based on both total shared DNA and number of segments. This tool builds on the earlier work of 23andMe scientists and Andrew Millard and attempts to distinguish among certain close relationships that other tools cannot. It claims to be “the most accurate relationship predictor available”, but the developer has taken extreme measures to prevent it from being compared to other tools. (See below)
2023–Brit Nicholson introduced the interactive SegcM, a tool that predicts relationships based on both total shared DNA and number of segments. This tool builds on the earlier work of 23andMe scientists and Andrew Millard and attempts to distinguish among certain close relationships that other tools cannot. It claims to be “the most accurate relationship predictor available”, but the developer has taken extreme measures to prevent it from being compared to other tools. (See below)
![]() 2023–MyHeritage revealed their new cM Explainer at RootsTech. The tool is based on the prior cM Solver by Larry Jones and has been enhanced to consider the ages of the two DNA relatives.
2023–MyHeritage revealed their new cM Explainer at RootsTech. The tool is based on the prior cM Solver by Larry Jones and has been enhanced to consider the ages of the two DNA relatives.

Updates to This Post
The text has been edited to reflect recent events. On 17 March, 2023, a tool under consideration was password protected by its developer to shield it from scrutiny. It was re-released on 22 March with new “terms and conditions” that explicitly prevent it from being used in this study. This behavior is profoundly unscientific, and I’m sad that the genealogical community had to witness it.
Posts in This Series
- Relationship Prediction Tools: Which Is Best?
- The Relationship Predictor Comparison: A First Peek
- In Which Citizen Science Finds an Error, and the Error Is Fixed
- The Science Behind Relationship Predictors
Hi Leah
Today, I have submitted various DNA match samples to your survey. I look forward, with interest, to the results.
I have a standalone program, “Relationship Estimator”, that was downloaded from https://dnaadoption.org/. It is very user friendly, and very accurate with its estimations.
Kind regards,
Neil McNicol (avid genetic genealogist – to the point of obcession)
Thank you!
There is also the DNAAdoption Relationship Estimator which was, I think, developed by Rob Warthen – https://dnaadoption.org/relationship-estimator-app/
Thanks for sharing!
I did this on your test survey on Facebook with one match. Should I do that one again or start with another one? I wasn’t sure if you were keeping the data on that one.
Thanks for asking! Please start with another one.
May I suggest that as well as the cMs, no. of segments and ages of the DNA matches, account should also be taken of the line of descent from the common ancestors, ie whether predominantly through maternal or paternal lines.
My examples are as follows: I have two 2c1R matches on my paternal grandmother’s side with whom our descent from our common ancestors is largely down the maternal line, and they both match me much more strongly than predicted, the female cousin with 221 cMs, 10 segments, and the male with 209 cMs, 8 segments, respectively. Their line of descent from our common ancestors goes ‘mother- grandmother – gr. grandmother – gr. x 2 grandparents’ while my line of descent goes ‘father – grandmother – gr. grandparents’.
Then I have another two 2C1R matches, this time on my paternal grandfather’s side, with whom our descent from our common ancestors is almost entirely down the paternal line, being ‘father – grandfather – gr. grandfather – gr. x 2 grandparents’ in my case, and ‘father – grandmother – gr. grandparents’ in their case. However, they only match me with 33 cMs, 3 segments (the female), and 32 cMs, 2 segments (the male), respectively. And to compound this discrepancy, our shared common ancestors in this case were first cousins of each other so one would expect the DNA matches between the descendants to be closer than average if anything, not the reverse.
I suspect it is the fact that males always inherit more maternal DNA than paternal due to the behaviour of the Y chromosome, which may be responsible for the unusually close maternal line matches compared to the strangely distant paternal matches above, and I have noticed that this pattern appears throughout all my known-cousin DNA matches to a greater or lesser degree, depending on the proportion of the maternal/paternal lines of descent in our connections to the common ancestors.
Maybe the relationship prediction researchers could consider looking into this.
The average amount of shared autosomal DNA isn’t affected by the line of descent (although the distribution can be), and most companies don’t tally X-DNA, so that’s not a factor.
In your case, you may have inherited more atDNA from your paternal grandmother than your paternal grandfather purely by chance. If so, that could affect all of your matches on your father’s side. You could test that hypothesis by mapping your chromosomes.
Very good overview. One criterion for “best” that has come up on the ISOGG Facebook discussion is the specificity of the prediction. For example, a prediction of one specific type relationship versus a prediction of half a dozen different relationships. The scoring of this aspect might have to be something like the degree of difficulty applied to diving, gymnastic, figure skating and other sports. Giving a very precise relationship prediction is better than giving one that has half a dozen possibilities, if the precise relationship is the right one.
I see the current state of the art in relationship predictors as a very significant step on a longer path. What relationship predictors have done has been extremely important and proven their value. But as with the inclusion of number of segments and the inclusion of ages of the matches, there is more to use for predictions than just total cMs. So, I look forward to full-information relationship predictors that will take into account all available information someday.
Agreed. As long as both predictions are correct, the more precise one is better. On the other hand, a precise prediction that is wrong is more likely to mislead, because it gives a false impression of authority. This is especially true for inexperienced genetic genealogists, who will be the ones relying most heavily on predictor tools in the first place and who may not recognize the limits of DNA-based predictions.
Unfortunately, we can no longer evaluate the “SegcM” tool because as of about 12:30 PM Pacific today, the developer has blocked access. Odd behavior.
I don’t think bringing in the age of matches in MH will work so well for me on my direct paternal side. My father was 42 when I was born, the next generation back the father was 45 years old, the next 42, the next 40 and even the two generations before that the fathers were 33.
I noticed MH gave my 2nd cousin 1R on my paternal side a 66% chance of being my 2nd cousin but only 3.2% chance of being my 2nd cousins son which he is. We share 175 cM. Another example is my 2nd cousin 2R who MH suggest is my 2nd cousin. We share 164 cM but MH don’t even give a suggested match of 2C 2R.
Although this advance may not help me on my paternal side I’m grateful for all advancements in DNA matching.
Thanks for sharing! What you describe is one reason we want to compare how well the tools perform.
Have just submitted my first entry to the survey. I will try to do more over the coming days as my paternal situation may be helpful to the results. How long does the survey last?
Thank you so much! There’s no end date as of yet for the survey.
Thanks, Geek! Unfortunately neither of my parents are still around, and my known cousins who have tested their DNA are distributed fairly evenly between Ancestry FTDNA, My Heritage and Gedmatch, not all in one place. How should I go about mapping my Chromosomes in this situation?
I suggest you join the DNA Painter User Group on Facebook for help with chromosome mapping.
Who is going to be doing the evaluating, i.e., are all the developers analyzing the results as a cooperating group each having a stake or is there an independent evaluator without any potential bias for any particular tool?
The data will be analyzed by Blaine Bettinger and myself, with criteria as described in the blog post.
Unfortunately, we can no longer evaluate the “SegcM” tool because as of about 12:30 PM Pacific today, the developer has blocked access. Odd behavior.
Well, if the only people analyzing the results developed one of the tools, in my mind, and I think that of other layman, is that it introduces the potential for bias. That perception could have been resolved by inviting participation in the design and analysis of the other developers. If that’s not possible, having an independent party evaluate and analyze the results would be a sort of peer review that would be more credible. As it is, if your tool comes out “first” there will always be a question of the validity of the result. It’s like McDonald’s having a hamburger taste test run by McDonald’s.
I’m not sure what you mean by “my” tool; I’m not a programmer. I came up with the *idea* of using probabilities for relationship prediction but not the probabilities themselves. My innovation stands no matter which probability set turns out to be best. And I certainly hope the probabilities improve over time with parameters like segment number (which I blogged about in 2017) and relative ages.
I’m not the source of any of the probability sets (nor is Blaine), so I don’t have any stake in which one “wins.” Our study is comparing three versions of Ancestry probabilities (the most up-to-date one on their website and two prior sets archived at DNA Painter), MyHeritage’s new probability set, and (until it was locked down) the SegcM ones. None of those three sources was invited to participate to avoid bias.
One person (who obviously has a lot invested in the outcome) has been poisoning the water since before the study was launched, much like Trump crying foul before the 2020 election. It’s both fascinating to watch and scary. Science doesn’t work by intimidation.
The point is moot now. Someone is apparently so terrified of independent scientists comparing his tool to others that he’s forbidden the practice. Now, users can only rely on his personal claims that he has “the most accurate relationship predictor available.”
I’ll be doing an insider’s peek at the data collection, quality control, and analysis on Friday, April 21 at 2 PM PDT. You can sign up here if you have questions or concerns about the study: https://www.eventbrite.com/e/618241124847
Will do!
I’ll be doing an insider’s peek at the data collection, quality control, and analysis on Friday, April 21 at 2 PM PDT. You can sign up here if you’re interested: https://www.eventbrite.com/e/618241124847